|
|
UMBC High Performance Computing Facility

System Description
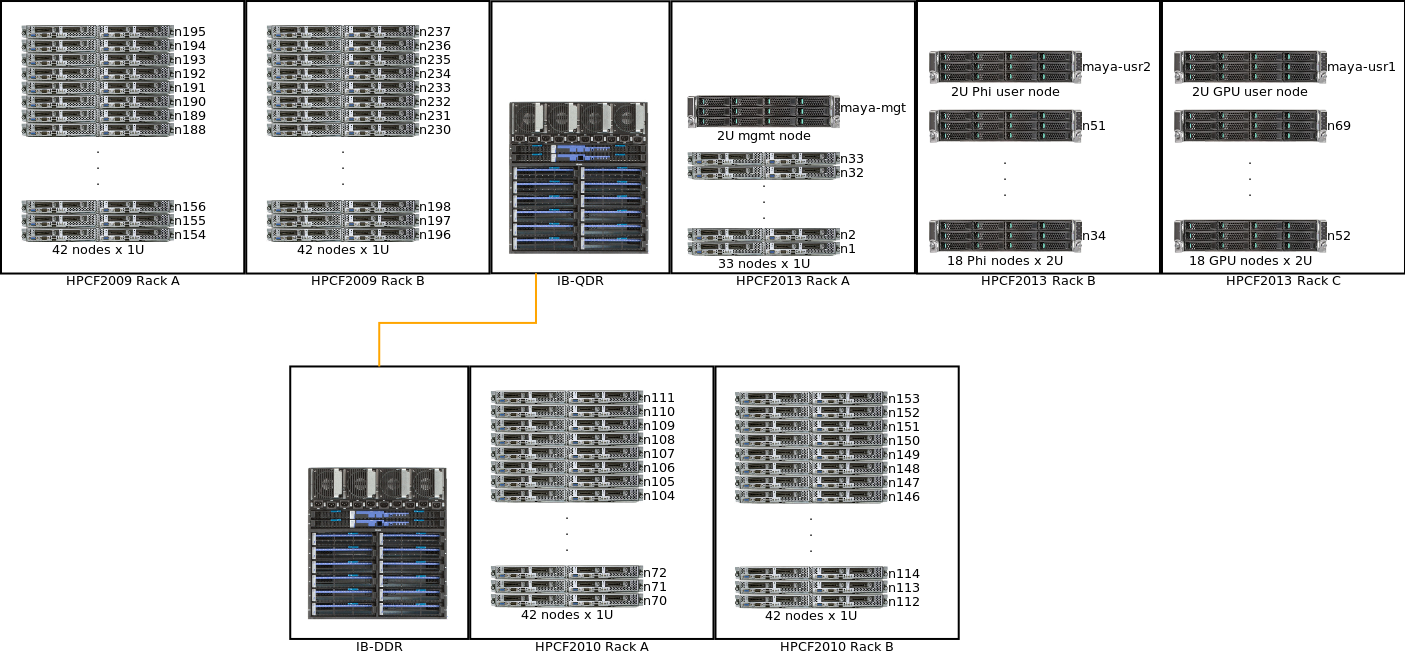 Some photos of the cluster are given below.
Some photos of the cluster are given below.

|

|

|

|

|

|

|

|

|

|

|

|

|
|
|
| Hardware Group | Rack | Hostnames | Description |
|---|---|---|---|
| hpcf2013 | A | maya-mgt | Management node, for admin use only |
| A | n1, n2, ..., n33 | CPU-only compute nodes. n1 and n2 are currently designated as development nodes |
|
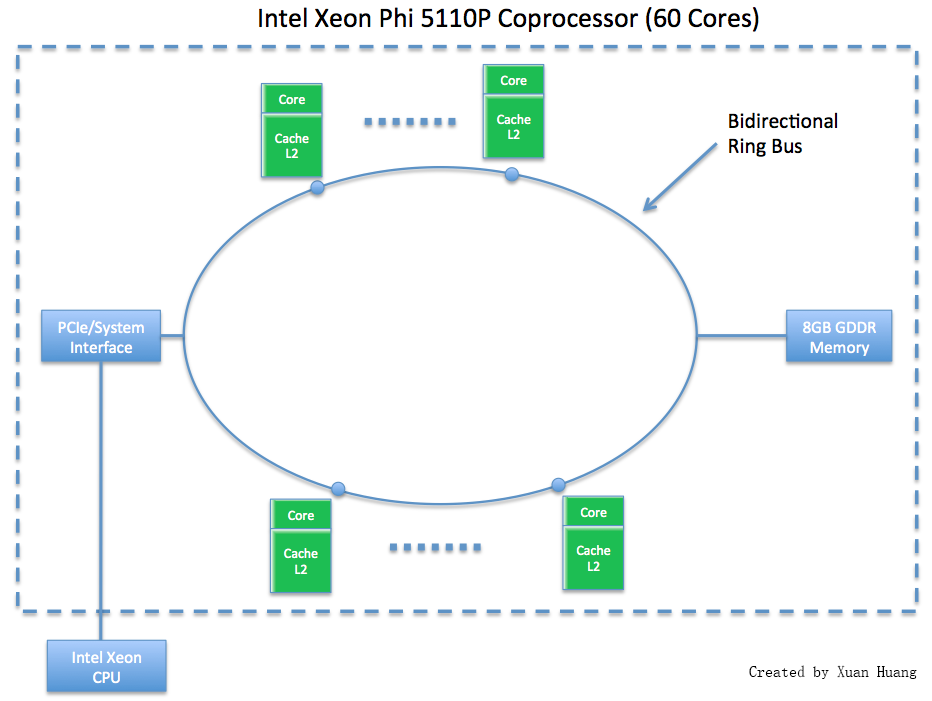
| B | maya-usr2 | User node with Phis | |
| B | n34, n35, ..., n51 | Compute nodes with Phis | |
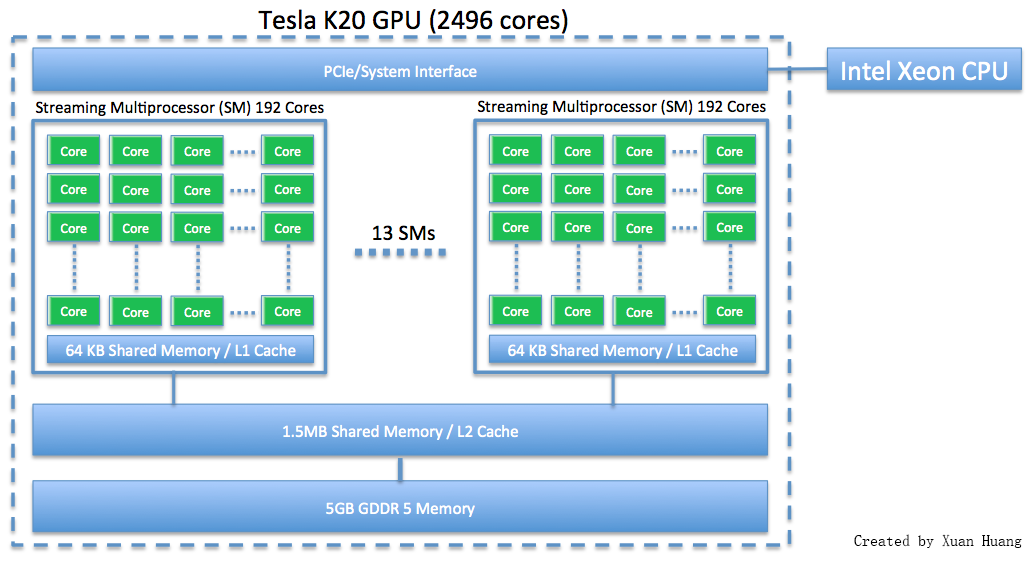
| C | maya-usr1 | User node with GPUs | |
| C | n52, n53, ..., n69 | Compute nodes witth GPUs | |
| hpcf2010 | A | n70, n71, ..., n111 | Compute nodes n70 is currently designated as a development node |
| B | n112, n113, ..., n153 | Compute nodes n112 is currently designated as a development node |
|
| hpcf2009 | A | n154, n155, ..., n195 | Compute nodes |
| B | n196, 198, ..., n237 | Compute nodes | |